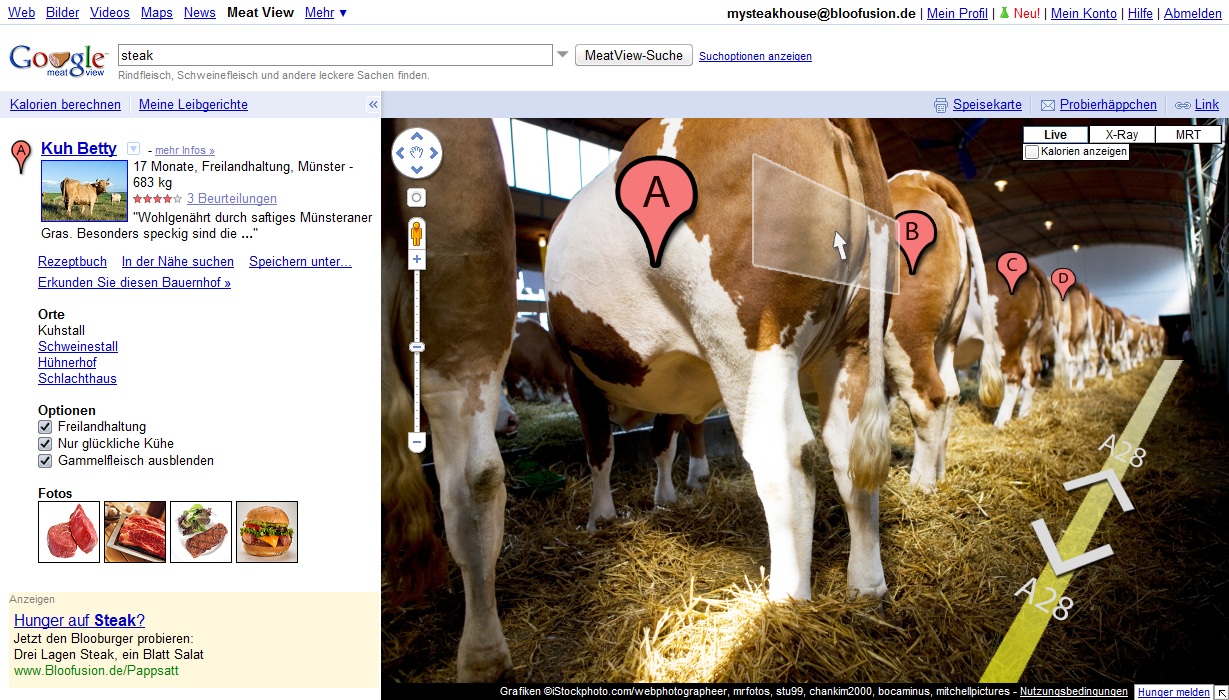
Wer glaubt, dass Google aufhört, innovative Produkte auf den Markt zu bringen, irrt. In den Google Labs sind jetzt zwei neue Tools im Beta-Test angelaufen, die auf den Fast-Food-Markt abzielen: Google MeatView und Google FatWords.
Für beide Programme hat Google bereits eine sehr stattliche Anzahl an Partnern gewonnen – darunter alle bekannten Burger-Ketten, aber auch viele kleinere Partner. Die Tools sollen zwei Herausforderungen meistern:
- Das Vertrauen in die Fast-Food-Industrie steigern
- Das enorme Marketing-Potenzial der Fast-Food-Käufer heben
Wir hatten Gelegenheit, die beiden neuen Dienste ausführlich zu testen. Auch wenn es wohl noch einige Monate dauern wird, bis diese überall verfügbar sind, sind diese Programme wohl für viele interessant, die mal schnell zwischendurch was essen wollen.
Google MeatView
 Auch Google ist wohl klar, dass Fleisch nicht gleich Fleisch ist. Gerade die zahlreichen Gammelfleischskandale der letzten Monate und Jahre haben die Strategen aus Mountain View wohl aufhorchen lassen.
Auch Google ist wohl klar, dass Fleisch nicht gleich Fleisch ist. Gerade die zahlreichen Gammelfleischskandale der letzten Monate und Jahre haben die Strategen aus Mountain View wohl aufhorchen lassen.
So bietet der neue Dienst Google MeatView Einblicke in deutsche Ställe und auf Weiden. Wer demnächst einen Burger kauft, sieht auf der Verpackung einen so genannte QR-Code, den man auslesen und dann bei MeatView nachschauen kann, woher das Fleisch stammt. Man kann aber auch den umgekehrten Weg gehen und sich aus dem großen Fundus eine bestimmte Kuh aussuchen und sich dann z. B. über Schlachttermine informieren. In Zukunft wird es dann über Partner-Shops möglich sein, Fleischprodukte eines ausgewählten Nutztiers direkt zu kaufen.
Interessant sind hier vor allem die zahlreichen Informationen und Optionen. So kann man z. B. nur nach “glücklichen Kühen” suchen oder Gammelfleisch direkt ausschließen. Definitiv fehlt hier noch die Auswahl von Bio-Fleisch, aber wie man aus Mountain View bereits hörte, wird auch diese Option bald nachfolgen.
Ungemach droht dem innovativen Dienst aber bereits von unerwarteter Seite, denn auch Tiere haben ein Recht auf Datenschutz. So meldete sich der oberste Tierdatenschützer der Nation, Peter Chaar, direkt zu Wort und beklagte die mangelnde Privatsphäre der Tiere. “Auch eine Kuh hat ein Recht auf ein anonymes Leben. Es ist schlicht nicht rechtens, dass man den Weg des Produktes zur Quelle zurückverfolgen kann. Hier geht mir die Datensammelwut Googles mal wieder deutlich zu weit.”
Ob das wirklich so ist, müssen wohl die Gerichte klären, denn Datenschutz für Nutztiere ist – vielleicht zu Recht – noch eine rechtliche Grauzone. Ein von uns befragter Bauer, der an dem Google-Programm teilnimmt, meinte hierzu: “Das geht doch echt zu weit. Bald hat auch noch ein Gänseblümchen Recht auf Datenschutz!”
Google FatWords
 Auch wenn Fast Food nach wie vor ein recht schlechtes Image hat, glaubt Google hier vieles besser machen zu können – und vor allem attraktive, bisher nicht genutzte Werbeflächen erschließen zu können.
Auch wenn Fast Food nach wie vor ein recht schlechtes Image hat, glaubt Google hier vieles besser machen zu können – und vor allem attraktive, bisher nicht genutzte Werbeflächen erschließen zu können.
So hat Google ein neues Programm namens Google FatWords gestartet (derzeit ebenfalls noch im Beta-Status). Über eine einzigartige Technologie werden dem Kunden Werbebotschaften direkt auf den Burger gebrannt. Und das, ohne den Geschmack zu verändern.
Dabei nutzt Google auch kontextsensitive Targeting-Maßnahmen. So sehen Familien durchaus andere Werbung als Teenies, die gerade von der Disko nach Hause fahren.

Auch die neue Funktion des Remarketing wurde direkt in FatWords integriert – wie man im Bild sieht. Unser Tester hatte sich vor einigen Tagen noch über eine neue SEO-Agentur informiert – und schon sah er dafür auch Werbung auf seinem Burger.
Derzeit sind FatWords leider nur auf Burgern erhältlich. Wer also bei bekannten Burger-Ketten einen Salat bestellt oder auch ein Frühstücksangebot wahrnimmt, erhält derzeit noch keine Werbung. Noch – denn: Das FatWords-Team arbeitet bereits an weiteren Werbeträgern. Dass das nicht so einfach ist, erklärte uns ein Mitarbeiter: “Versuchen Sie mal, mit einem Laser Werbebotschaften in Rührei zu brennen. Das geht gar nicht.”
Hier gibt es also noch viel Forschungsbedarf, der aber sicherlich angesichts der Attraktivität der Zielgruppe gerechtfertigt ist.
Fazit
Google betritt mit den beiden neuen Diensten MeatView und FatWords Neuland. Interessant sind die neuen Dienste auf jeden Fall, auch wenn es noch kleine Detailprobleme gibt und natürlich auch noch rechtliche Bedenken.
Schlussendlich muss sich natürlich jeder fragen, ob er zumindest MeatView überhaupt nutzen möchte, denn Fleischkonsum lebt wohl gerade davon, dass man der Kuh vorab nicht in die Augen (bzw. bei MeatView auf den Hintern) gucken muss. Es könnte also durchaus sein, dass Google der Branche hier einen Bärendienst erweist und so für sinkenden Konsum von Fleisch sorgt. FatWords ist aber definitiv ein interessantes Tool, das die Offline- und die Online-Welten perfekt miteinander verbinden kann.